새소식
반응형
안녕하세요 오늘은 머신러닝 또는 딥러닝 모델의 성능 평가방법에 대해 알아보고자 합니다.

위 그림처럼 학습된 모델의 성능이 좋은지 안좋은지는 어떻게 알 수 있을까요?
학습된 모델의 성능을 평가하기 위해 Confusion Matrix를 많이 활용합니다.
아래그림처럼 MNIST데이터를 학습한 모델에게 여러가지 숫자를 보여준다고 가정해보겠습니다.

1~4까지의 숫자들을 각각 5번씩 보여주었다고 가정해보고 입력값(X)에 따른 모델의 예측값(Y)을 행렬로 정리해보겠습니다.

위 테이블을 보시면 학습된 모델에게 '1'을 5번 보여줬을때 2번 맞췄다는걸 알 수 있습니다.
'2'는 5번, '3'은 3번 , '4'는 4번 맞춘걸 알 수 있습니다.
이렇게 학습된 모델의 입력값과 예측값을 정리한 테이블을 Confusion Matrix라고 부르게 됩니다.
Confusion Matrix를 통해서 모델의 성능지표인 Accuracy, Precision, Recall, F1 Score를 계산하게 됩니다.
Python을 이용해서 위 예시로 만든 Confusion Matrix를 구현해보도록 하겠습니다.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
sns.set(font_scale = 2)
cMatrix = [[2,1,1,1],[0,5,0,0],[0,1,3,1],[1,0,0,4]]
df_cMatrix = pd.DataFrame(cMatrix, index = ["1","2","3","4"], columns = ["1","2","3","4"])
plt.figure(figsize = (10,7))
plt.title('Confusion Matrix')
sns.heatmap(df_cMatrix, annot=True)Seaborn함수를 이용해서 Heatmap으로 표현을 하면 아래 그림과 같은 결과가 나오는걸 확인할 수 있습니다.
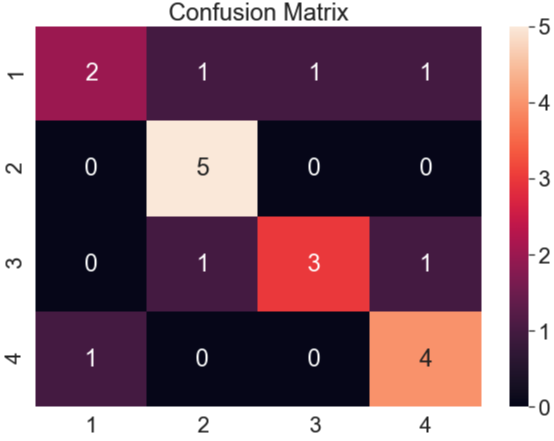
입력값 중 가장 예측률이 높은 부분에 대한 색상이 밝게 표시되어 있는걸 볼 수 있습니다.
현재는 예측결과들에 대해 5번씩 밸런스하게 나와있어서 눈으로 정확도를 대략적으로 계산할 수 있지만
실제 데이터의 경우엔 아닌 경우도 많습니다.
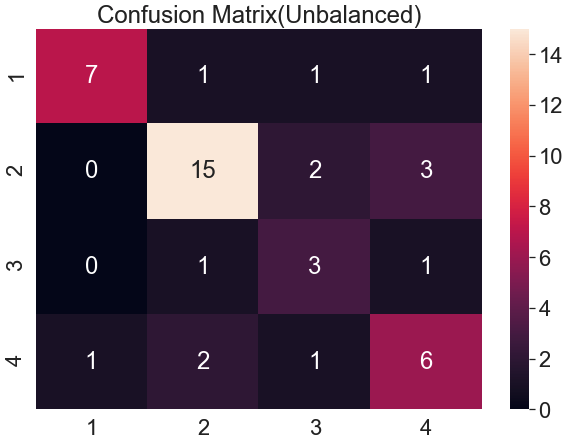
위 그림을 보시면 '1'의 예측값의 수는 10개, '2'는 20개, '3'은 5개, '4'는 10개인 것을 확인할 수 있습니다.
그래서 보통 Confusion Matrix를 만든 후 행렬 값에 Normalization 적용하여 더 보기 쉽게 처리해줍니다.
Numpy 라이브러리를 같이 활용하여 Normalization 된 Confusion Matrix를 만들어보겠습니다.
import numpy as np
total = np.sum(cMatrix2, axis=1)
norCM = cMatrix2/total[:,None]
df_norCM = pd.DataFrame(norCM,index = ["1","2","3","4"], columns = ["1","2","3","4"])
plt.figure(figsize = (10,7))
plt.title('Confusion Matrix(Normalization)')
sns.heatmap(df_norCM, annot=True)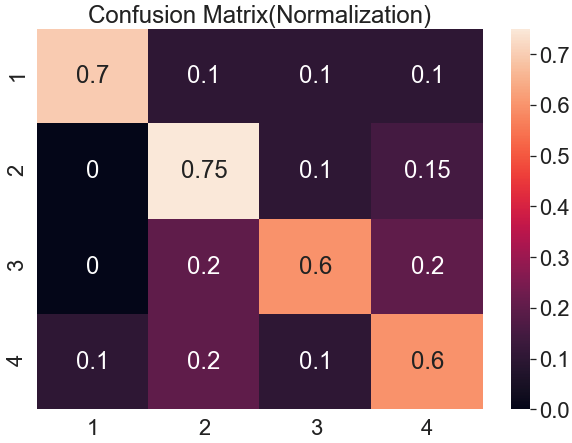
Normalization처리를 해주니 각 행별 예측값에 대해 더 직관적으로 볼 수 있습니다.
다음 포스팅에는 Confusion Matrix를 활용하여 Accuracy, Precision, Recall, F1 Scroe를 계산하는 방법에 대해 알아보겠습니다.
| 모델의 성능 평가방법(2) - accuracy, precision, recall, F1 score (0) | 2021.10.11 |
|---|---|
| 주성분 분석, PCA(Principal Component Analysis) 쉽게 이해하기(2) (1) | 2021.09.18 |
| 주성분 분석, PCA(Principal Component Analysis) 쉽게 이해하기(1) (0) | 2021.09.11 |
| KNN(K-Nearest Neighbor)과 색상 분류(2) (0) | 2021.08.29 |
| KNN(K-Nearest Neighbor)과 색상 분류(1) (0) | 2021.08.21 |
소중한 공감 감사합니다